The Plan
Ta kartka została eksportowana z Markdowna w stylu GitHuba. Dostępna jest też jako wyrenderowany PDF tutaj.
Wprowadzenie
Czego szukamy?
- Rozwiązania problemów o wielu możliwych rozwiązaniach, z których chcemy wybrać optymalne
- Genetyka - najdłuższy wspólny podciąg
- Logistyka - problem komiwojażera
- Kombinatoryka
- Teoria gier - szukanie strategii wygrywającej
Jakie są problemy?
- Możliwych kombinacji może być bardzo dużo
- Trudno wygenerować możliwe rozwiązania
- Nie ma dobrego sposobu na opisanie problemu bądź sensowną implementację
Z czego skorzystamy:
- Obserwacja: Problemy często się powtarzają i się pokrywają
- Rozwiązanie problemu zależy od tego jak rozwiązaliśmy podproblemy
Przykład problemu - Zadanie Podciąg Jasia
Mamy ciąg liczb . Chcemy wybrać taki podciąg złożony z , z następującym ograniczeniem: w podciągu nie mogą występować sąsiednie elementy:
Należy podać maksymalną sumę podciągu.
- Przykład: 10 1 1 10. Rozwiązanie to 20.
- Inny przykład: -2 2 -1 3 5. Rozwiązanie to 7.
Co robić?
- Proste rozwiązanie: sprawdzić wszystkie podciągi
- O wiele lepsze: Programowanie dynamiczne
Rozwiązanie przykładu
Przypuśćmy teraz, że znamy już rozwiązanie dla każdego prefiksu poza całym ciągiem .
Wprowadźmy oznaczenie, że oznacza rozwiązanie (czyli maksymalną sumę) dla ciągu . W szczególności znamy wartości .
Jak może wyglądać ? Są dwie możliwości: może albo zawierać , albo go nie zawierać.
- Jeżeli zawiera, to dodajemy do wyniku i odrzucamy . Reszta rozwiązania może się składać z dowolnych pozostałych elementów. Tak się składa, że znamy tę wartość - jest to . Otrzymujemy .
- Jeżeli go nie zawiera, to przypadek jest prostszy: rozwiązanie składa się z pierwszych elementów, czyli maksymalna suma jest równa .
Tym samym otrzymujemy wzór na :
Rozszerzenie
W ten sposób znaleźliśmy sposób na rozszerzenie rozwiązania z do . Ponieważ wyniki zawsze są optymalne, możemy w ten sposób policzyć wszystkie wartości .
Trochę terminologii, która się przyda
Stan to pewien podproblem, który wybraliśmy sobie do rozwiązania. W tym wypadku są to prefiksy , ale nic nie szkodzi aby były to np. sufiksy. Stan przechowuje pewną wartość, tutaj jest to optymalna suma podciągu.
Przejścia to wzory które odwołują się do mniejszych podproblemów, które zawierają się w rozpatrywanym problemie. Chcemy w nich rozpatrzyć wszystkie możliwe sposoby, na jakie może powstać rozwiązania. Stany muszą być tak dobrane, aby istniały odpowiednie przejścia.
Trudność: wymyślić takie stany i przejścia, które rozpatrzą wszystkie możliwości i tym samym poprawnie znajdą wynik.
Łańcuchy
Powiemy, że jest zależne od jeżeli można wybrać takie przejścia, że można dojść ze stanu do (przejście z do tzn. wartość pojawia się we wzorze na wartość ).
Zależności w dynamiku są o tyle ważne, że musi istnieć uporządkowanie topologiczne stanów: to znaczy takie, że nie ma dwóch takich stanów i , że jest zależne od i występuje później w uporządkowaniu niż .
Innymi słowy, nie może być cyklicznej zależności. (Nawiasem mówiąc, to znaczy że graf przejść i stanów jest acykliczny)
W tym przykładowym zadaniu graf zależności wygląda mniej więcej o tak:
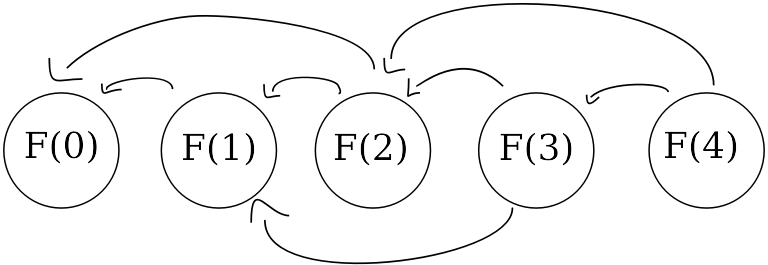
Implementacja
Na początek:
- Trzeba pamiętać o przypadkach brzegowych. Zwykle wystarczy poszukać, kiedy wymyślone przez nas wzory nie działają. W tym wypadku jest tak dla i , bo odwołują się do i . Nasze przypadki brzegowe można rozwiązać np. tak:
- Należy znaleźć odpowiednie uporządkowanie na podstawie zależności, które mamy. Zwykle uporządkowanie będzie się narzucać (w zadaniu jest bardzo łatwo, wystarczy odwiedzać kolejno stany ).
A teraz do praktyki:
Rekurencja
Najłatwiej jest podejść rekurencyjnie i bezpośrednio wykorzystać wzory. Nie musimy wtedy dbać o kolejność odwiedzanych stanów.
def F(n): if n == 1: return max(0, A[1]) else if n == 2: return max(0, A[1], A[2]) else: return max(F(n - 1), F(n - 2) + A[n])
Niestety, w ten sposób rozwiązanie jest wykładnicze (jaka jest jego złożoność?). Wystarczy jednak lekko ulepszyć podejście.
Tabulacja
Zapiszemy kolejne wartości funkcji w tablicy i odwiedzimy i wypełnimy kolejne jej komórki w odpowiedniej kolejności.
F[1] = max(0, A[1]) F[2] = max(0, A[1], A[2]) for i = 3, 4, ..., n: F[i] = max(F[i - 1], F[i - 2] + A[n])
Utrzymywanie tylko koniecznych stanów
Technika ta zmniejszy zużycie pamięci. Zauważmy, że potrzebne jest nam do policzenia jedynie i . Możemy się go pozbyć po 2 iteracjach. W tym zadaniu możemy to jeszcze bardziej uprościć i trzymać 3 zmienne, które będą oznaczać obecne .
a = max(0, A[1]) # F(i - 2) b = max(0, A[1], A[2]) # F(i - 1) c = 0 # F(i) for i = 3, 4, ..., n: c = max(a, b + A[i]) a = b b = c
Rozwiązania oczywiście zakładają – wystarczy dopisać obsługę przypadków brzegowych.
Podsumowanie - schemat działania
- Znajdź podproblemy. W jaki sposób można opisać wszystkie przypadki? Jak opisać je rekurencyjnie? (przypadek składa się z pewnego fragmentu plus mniejszych przypadków)
- Wybierz stany i przechowywane przez nie wartości, oraz
- Wybierz przejścia, tak, żeby było dobrze.
- Dobierz uporządkowanie, kolejność odwiedzanych stanów.
- Wypisz przypadki krańcowe, dla których nie działają wzory.
- Zwróć wynik dla stanu, który opisuje cały problem.
Techniczne:
- Podliczenie złożoności obliczeniowej, zarówno pamięciowej i czasowej
- Jeżeli czasowa jest za duża, rozważ inne stany i przejścia bądź użyj odpowiedniej struktury danych, poszukaj, które stany są niepotrzebne, etc. (jest dużo sposobów)
- Jeżeli pamięciowa jest za duża, sprawdź, czy da się utrzymywać mniej stanów w pamięci.
- Wybranie sposobu implementacji:
- Rekurencja (z odpowiednim usprawnieniem – memoizacja).
- Tabulacja
- z góry na dół (top-down): stany odwołują się niżej, prościej
- z dołu na górę (bottom-up): stany aktualizują stany zależne, czasami lepiej
Klasyki
Rozważymy teraz kilka klasycznych problemów:
- problem plecakowy
- problem wydawania reszty
- najdłuższy wspólny podciąg
Problem plecakowy (Knapsack problem)
Mamy przedmiotów opisanych wagami oraz wartościami . Dany jest nam do dyspozycji plecak, który może pomieścić przedmioty o sumarycznej wadze . Jaką maksymalną sumaryczną wartość przedmiotów możemy uzyskać?
- Podproblemy: problem składa się z dwóch ważnych cech: pojemności plecaka i przedmiotów. Trzeba nadać jakąś kolejność przedmiotom.
- Stan: Niech stanem będzie , gdzie to obecna waga przedmiotów w plecaku a to ilość rozpatrzonych przedmiotów. Wartość stanu to maksymalna wartość przedmiotów o wadze .
- Przejścia: Możemy wziąć -ty przedmiot, albo tego nie zrobić. Mamy więc Strażnik (sentinel): Możemy przyjąć że dla jest .
- Uporządkowanie: Dosyć intuicyjne: rosnące wartości , a tam rosnące wartości , bądź na odwrót.
- Przypadki krańcowe: Najlepiej dodać strażnika, że .
- Wynik:
Złożoność: .
Problem wydawania reszty
Mamy nominałów o wartościach i chcemy nimi wydać wartość . Nominałów można używać dowolnie wiele razy. Chcemy użyć minimalnej liczby nominałów.
- Podproblemy: Liczy się dotychczas wydana kwota i rozpatrzone nominały.
- Stan: – minimalna liczba nominałów spośród pierwszych , aby otrzymać wartość .
- Przejścia: .
- Uporządkowanie: Tak jak problem plecakowy.
- Przypadki krańcowe: Tak jak problem plecakowy – strażnik jest dobrym pomysłem.
- Wynik: .
Złożoność: .
Najdłuższy wspólny podciąg (Longest Common Subsequence)
Przez podciąg ciągu definiujemy taki ciąg , że istnieje taki ciąg indeksów , że dla każdego zachodzi .
Mając dane dwa ciągi, i , znajdź długość jak najdłuższego ciągu , że jest podciągiem oraz jednocześnie. o maksymalnej długości nazywany jest najdłuższym wspólnym podciągiem - LCS.
- Podproblemy: Prefiksy obu ciągów.
- Stan: - długość LCS dla oraz .
- Przejścia: Dwa przypadki: albo i są w LCS, albo nie. Jeżeli tak, to dodajemy 1 do wyniku i skracamy oba prefiksy. W innym wypadku możemy przejść do dowolnej prefiksu.
- Uporządkowanie:
- Przypadki krańcowe: Jeżeli jeden z ciągów jest pusty, to LCS jest pusty.
- Wynik:
Złożoność:
Odtwarzanie wyniku
A co jeżeli chcemy odtworzyć wynik? (W wypadku LCS: Jak odzyskać ciąg ?)
Przejścia symbolizują decyzje podejmowane przy budowie wyniku. Wystarczy więc przechowywać dodatkową tablicę, która utrzymuje optymalną decyzję. Remisy mogą być roztrzygane dowolnie (różne sposoby pozwalają na wygenerowanie wszystkich możliwych rozwiązań).
Przykładowo dla LCS: niech symbolizuje wybór.
A w kodzie LCS wyglądać to będzie mniej więcej tak:
p, q = n, m c = [] while (p, q) != (0, 0): if B(p, q) == TAKE: c += a[p] # == b[q] p -= 1; q -= 1 else if B(p, q) == CUT_A: p -= 1 else if B(p, q) == CUT_B: q -= 1 c.reverse()
W ten sposób odtworzymy znaki od końca - gdy dojdziemy do stanu , kończymy działanie i odwracamy ciąg .
Taka technika często nazywana jest backtracking, czyli podążanie za swoimi śladami.
Warto zauważyć, że gdy używamy backtrackingu problematyczne może być ograniczanie zużycia pamięci.
Długość cyklu Collatza
Prosty (i mniej klasyczny) problem na którym można dobrze zobrazować działanie memoizacji to problem znalezienia długości ciągu Collatza.
Zaczynamy od pewnej liczby całkowitej . Jeżeli jest parzysta, to . W przeciwnym wypadku . Postępujemy analogicznie z . Długość cyklu Collatza to najmniejsze dla którego . Nawiasem mówiąc, hipoteza Collatza mówi, że takie istnieje dla każdego .
Oznaczmy długość ciągu Collatza dla jako .
Powiedzmy że chcemy policzyć maksymalne spośród liczb od do .
Moglibyśmy dla każdej z nich iteracyjnie liczyć , ale zamiast tego możemy skorzystać z następującego podejścia (memoizacji):
Zauważmy, że oraz (gdzie to następna liczba w ciągu Collatza po ). Tak więc licząc pewne możemy zapisywać jakie liczby już odwiedziliśmy i policzyliśmy dla nich - jeżeli potem do nich trafimy, możemy odczytać wartość i od razu ją zwrócić, zamiast liczyć ją ponownie.
# lim to pewna eksperymentalnie wyznaczona wartość # - maksymalna wartość, jakiej równy będzie n vis = array(lim, False) memo = array(lim, 0) def C(n): if n == 1: return 0 else if vis[n]: return memo[n] else: vis[n] = True memo[n] = C(n // 2 if n % 2 == 0 else 3*n + 1) + 1 return memo[n]
Najlepiej zamiast tablicy skorzystać ze struktury rodzaju mapy/słownika (np. std::map w C++) – wtedy nie musimy przewidywać, ile pamięci potrzebujemy.
Memoizacja jest tutaj dobrym wyborem, bo trudno przewidzieć w jakiej kolejności należy przejść bo liczbach, aby uporządkowanie było poprawne – ciąg Collatza jest bardzo chaotyczny, na zmianę rośnie i maleje.